








Feature flags service outage

Contents
Internal post-mortem: https://github.com/PostHog/incidents-analysis/pull/120
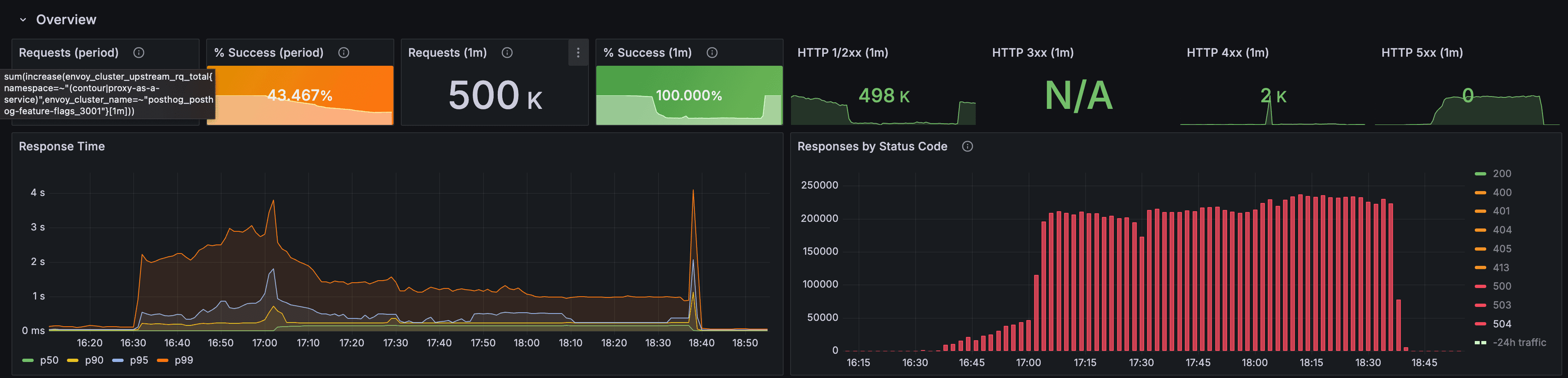
On September 29, 2025, the PostHog Feature Flags service experienced an outage lasting 1 hour and 48 minutes, from 16:58 to 18:46 UTC. During this period, approximately 78% of flag evaluation requests in the US region failed with HTTP 504 errors.
Summary
A database connection timeout reduction from 1 second to 300 milliseconds coincided with elevated load on our writer database from person ingestion. This combination triggered cascading failures in our connection retry logic, resulting in a service-wide outage. Recovery was significantly delayed by hardcoded configuration values and procedural failures in our incident response.
Timeline
- 16:58 UTC – Writer database begins experiencing connection saturation from person ingestion post-deployment workload
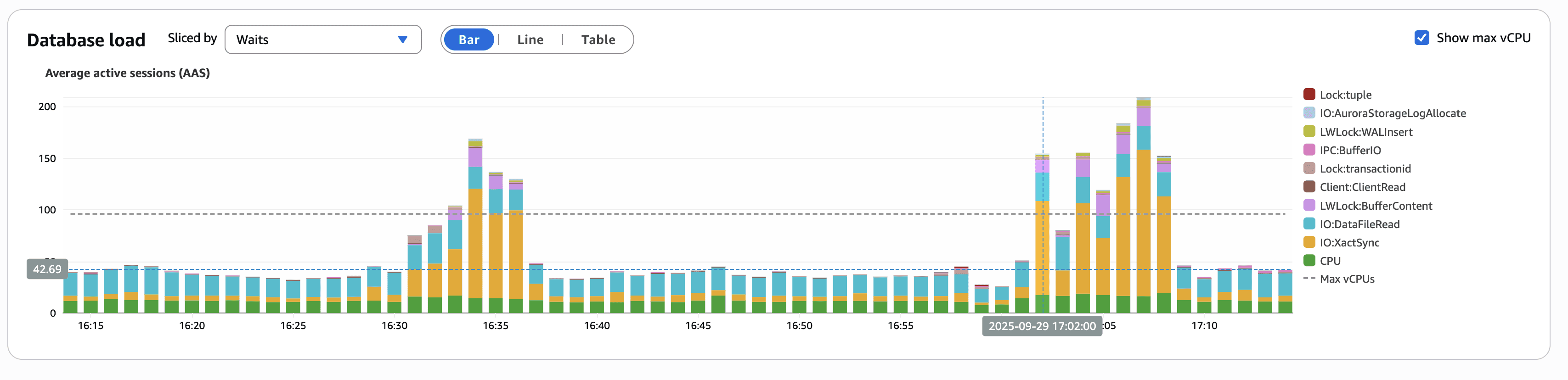
17:02 UTC – Unrelated deployment reduces database connection timeout from 1s to 300ms
17:05 UTC – Initial pods begin failing database connections and entering crash loops
- 17:12 UTC – Retry amplification begins overwhelming the writer database

- 17:25 UTC – Incident declared, rollback attempted
- 17:40 UTC – Rollback fails due to ArgoCD configuration issues
- 18:15 UTC – Manual configuration changes deployed
- 18:46 UTC – Service fully restored
Full service degradation timeline
Root cause analysis
The outage resulted from three compounding factors:
Configuration change timing: A connection timeout reduction deployed during a period of database stress created conditions where pods could not establish connections within the new timeout window.
Retry amplification: Our retry logic lacked circuit breakers and exponential backoff, causing failed connection attempts to multiply rapidly. This transformed a manageable database load issue into complete service unavailability.
Health check configuration: Kubernetes continued routing traffic to pods in crash loops for up to 45 minutes due to improperly configured liveness and readiness probes.
The incident duration was extended by operational failures: timeout values were hardcoded in the application rather than externalized as configuration, requiring a full deployment cycle to modify. Additionally, our standard ArgoCD rollback procedure failed due to misconfigured permissions.
Impact
- 78% of feature flag evaluation requests failed in the US region
- All flag types were affected, including read-only flags that did not require writer database access
- Customers experienced HTTP 504 errors regardless of their specific flag configurations
Remediation
Immediate actions (completed)
- Database connection timeouts moved to runtime configuration
- Timeout values increased to accommodate peak load scenarios
Short-term improvements (Follow along here)
Read/write path separation: Implementing distinct connection pools and failure domains for read-only operations versus write operations. Read-only flag evaluations will continue functioning during writer database issues.
Circuit breaker implementation: Adding circuit breakers with exponential backoff to prevent retry amplification during connection failures.
Health check optimization: Configuring aggressive liveness and readiness probes to remove failing pods from rotation within seconds rather than minutes.
Rollback procedure documentation: Creating detailed runbooks for ArgoCD rollbacks with proper permission configurations and validation steps.
Long-term improvements (Q4 2025 – Q1 2026)
- Development of specialized tooling for rapid pod termination during incidents
- Comprehensive load testing to validate connection pool behavior under contention
- Quarterly incident response drills to ensure operational readiness
Lessons learned
This incident highlighted critical gaps in our defensive architecture and operational procedures. The coupling of read and write operations created unnecessary failure domains, while our retry logic lacked basic protective mechanisms against amplification. Most significantly, our incident response was hampered by inflexible configuration management and untested rollback procedures.
The architectural improvements underway will provide proper isolation between different operational modes of the feature flags service. This separation, combined with improved circuit breaking and configuration management, will prevent similar cascading failures in the future.